简单栈介绍
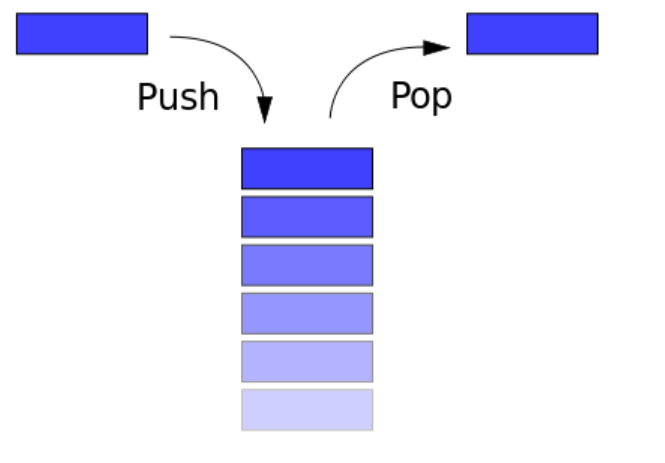
栈是一种典型的后进先出(Last in First Out)的数据结构,其操作主要有压栈(push)和出栈(pop)两种操作,如下图所示(维基百科)。两种操作都操作栈顶,当然,它也有栈底。
高级语言在运行时都会被转换为汇编程序,在汇编程序运行过程中,充分利用了这一数据结构。每个程序在运行时都有虚拟地址空间,其中某一部分就是该程序对应的栈,用于保存函数调用信息和局部变量。此外,常见的操作也是压栈与出栈。需要注意的是,程序的栈是从进程地址空间的高地址向低地址增长的。
函数调用栈
C语言函数调用栈
程序的执行过程可看作连续的函数调用。当一个函数执行完毕时,程序要回到调用指令的下一条指令(紧接call指令)处继续执行。函数调用过程通常使用堆栈实现,每个用户态进程对应一个调用栈结构(call stack)。编译器使用堆栈传递函数参数、保存返回地址、临时保存寄存器原有值(即函数调用的上下文)以备恢复以及存储本地局部变量。
不同处理器和编译器的堆栈布局、函数调用方法都可能不同,但堆栈的基本概念是一样的。

需要注意的是,32位和64位程序有以下简单的区别
x86:
函数参数在函数返回地址的上方

x64:
System V AMD64 ABI (Linux、FreeBSD、macOS 等采用)中前六个整型或指针参数依次保存在RDI,RSI,RDX,RCX,R8和R9寄存器中,如果还有更多的参数的话才会保存在栈上。
内存地址不能大于0x00007FFFFFFFFFFF,6个字节长度,否则会抛出异常。
# gdb.attach(p)
g = lambda x: gdb.attach(x)
# send() sendline() sendafter() sendlineafter()
s = lambda x: p.send(x)
sl = lambda x: p.sendline(x)
sa = lambda x,y: p.sendafter(x,y)
sla = lambda x,y: p.sendlineafter(x,y)
# recv() recvline() recvuntil()
r = lambda x: p.recv(x)
rl = lambda : p.recvline()
ru = lambda x: p.recvuntil(x)
r_leek_libc_64 = lambda : u64(p.recvuntil(b'\x7f')[-6:].ljust(8,b'\x00'))
r_leek_libc_32 = lambda : u32(p.recvuntil(b'\xf7')[-4:])